Redis 各种数据结构
字符类型 String
# 储存
set key value
# 获取
get key
# 删除
del key
注意,这个虽然叫做 String 但是它并不是一般意义上的字符串类型,它可以是 字符串、整数 或者浮点数
字符串的自增和自减命令
当用户将一个值存储到 Redis 字符串里面的时候,如果这个值可以被解释(interpret)为十进制整数或者浮点数,那么 Redis 会察觉到这一点,并允许用户对这个字符串执行各种 INCR * 和 DECR * 操作。
如果用户对一个不存在的键或者一个保存了空串的键执行自增或者自减操作,那么 Redis 在执行操作时会将这个键的值当作是 0 来处理。
如果用户尝试对一个值无法被解释为整数或者浮点数的字符串键执行自增或者自减操作,那么 Redis 将向用户返回一个错误。
命令操作实例
使用:get 、 set 、 del 、 incr、 decr 等命令操作 string 数据
127.0.0.1:6379> set hello world
OK
127.0.0.1:6379> get hello
"world"
127.0.0.1:6379> del hello
(integer) 1
127.0.0.1:6379> get hello
(nil)
127.0.0.1:6379> get counter
"2"
127.0.0.1:6379> incr counter
(integer) 3
127.0.0.1:6379> get counter
"3"
127.0.0.1:6379> incrby counter 100
(integer) 103
127.0.0.1:6379> get counter
"103"
127.0.0.1:6379> decr counter
(integer) 102
127.0.0.1:6379> get counter
"102"
散列类型 Hash

这个其实就是 HashMap 那样使用
# 储存语法
hset key field value
# Redis 的 Hash 可以同时插入多个数据
hset key field01 value01 field02 value02 field03 value03
# 获取
hget key field
# 获取所有列
hgetall key
# 删除
hdel key field
使用示例
由于 hash 类型存储的是一个键值对,比如数据库有以下一个用户表结构
| id | name | age |
|---|
将以上信息存入 redis,用表明 user:id 作为 key,用户属性作为值:
# hset 可以同时插入多个字段
# 语法:
hset key field01 value01 field02 value02 field03 value03
# 使用如下(注意,这里的 user:1 整个为一个 key):
hset user:1 name 张三 age 18
使用哈希存储会比字符串更加方便直观

列表类型 List
是安装插入顺序排序的,可以插到左边(lpush,头部)也可以插入到右边(rpush,尾部)
使用实例
# 将元素加入到列表左边(就像压栈,先进后出)
lpush key value
# 将元素加入到列表右边(先进先出)
rpush key value
#============例如==============
127.0.0.1:6379> lpush test 1 2 3 4 5
127.0.0.1:6379> rpush test 6 7 8 9
127.0.0.1:6379> LRANGE test 0 -1
#===输出====
1) "5"
2) "4"
3) "3"
4) "2"
5) "1"
6) "6"
7) "7"
8) "8"
9) "9"
#=============END============
# 获取(range 范围 从 0 开始,可以使用 -1 表示结尾)
lrange key start end
# 删除(使用弹栈的方式,删除一个列表左边的元素,并将元素返回)
lpop key
集合类型 Set
就是一个不允许插入重复元素的集合
# 存储
sadd key value
# 获取(members :成员) set 集合的所有元素
smembers key
# 删除(remove) set 集合的某个元素
srem key value
交集运算
以下是一个使用 SINTER 命令获取 Set 交集的实际例子和对应的命令:
假设有两个 Set,分别为 "set1" 和 "set2",它们包含一些元素。
添加元素到 Set:
SADD set1 element1 element2 element3
SADD set2 element2 element3 element4在上述命令中,将元素添加到 Set "set1" 和 "set2" 中。
获取 Set 交集:
SINTER set1 set2使用
SINTER命令获取 Set "set1" 和 "set2" 的交集。返回的结果是包含两个 Set 共同元素的集合。
需要注意的是,使用 SINTER 命令获取的交集结果是一个新的 Set,其中包含了两个 Set 共同存在的元素。可以通过命令的返回结果获取交集的元素。
并集运算
可以使用 SUNION 命令获取多个 Set 的并集。以下是一个使用 SUNION 命令获取 Set 并集的实际例子和对应的命令:
假设有两个 Set,分别为 "set1" 和 "set2",它们包含一些元素。
添加元素到 Set:
SADD set1 element1 element2 element3
SADD set2 element3 element4 element5在上述命令中,将元素添加到 Set "set1" 和 "set2" 中。
获取 Set 并集:
SUNION set1 set2使用
SUNION命令获取 Set "set1" 和 "set2" 的并集。返回的结果是包含两个 Set 所有元素的集合。
需要注意的是,使用 SUNION 命令获取的并集结果是一个新的 Set,其中包含了两个 Set 中的所有元素。可以通过命令的返回结果获取并集的元素。
有序集合 ZSet
同上面那个 set 集合一样,都是不能插入重复元素的集合,但是这个集合多了个 sort 功能
有序集合和散列(Hash)一样,都 用于存储键值对:有序集合的键被称为成员(member),每个成员都是各不相同的;
而有序集合的值则被称为分值(score),分值必须为浮点数。
有序集合是 Redis 里面唯一个既可以根据成员访问元素(这一点和散列一样),又可以根据分值以及分值的排列顺序来访问元素的结构。

每个元素都会关联一个 double 类型的分数。redis 正是通过分数来为集合中的成员进行从小到大的排序。
# 存储(需要指定分数,分数可以随便填,反正是从小到大排序的)
# 语法:
zadd key score member
# 在尝试向有序集合添加元素的时候,命令会返回新添加元素的数量(所以插入的对象已存在时会返回 0)
#============例如==============
127.0.0.1:6379> zadd test 10 temp01
127.0.0.1:6379> zadd test 8 temp02
127.0.0.1:6379> zadd test 12 temp03
# 遍历有序集合
127.0.0.1:6379> ZRANGE test 0 -1
#===输出====
1) "temp02"
2) "temp01"
3) "temp03"
#=============END============
# 获取
zrange key start end
# 删除
zrem key value
有序集合的并集和交集运算
有序集合的并集运算和交集运算在刚开始接触时可能会比较难懂,所以本节将使用图片来展示交集运算和并集运算的执行过程。
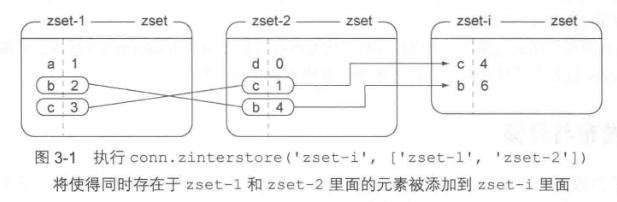
1、交集运算
图3-1 展示了对两个输人有序集合执行交集运算并得到输出有序集合的过程,这次交集运算使用的是默认的聚合函数 sum,所以输出有序集合成员的分值都是通过加法计算得出的。
2、并集运算
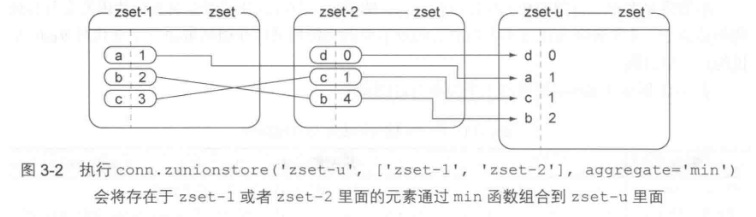
并集运算和交集运算不同,只要某个成员存在于至少一个输人有序集合里面,那么这个成员就会被包含在输出有序集合里面。
图3-2展示了使用聚合函数min执行并集运算的过程,min 函数在多个输入有序集合都包含同一个成员的情况下,会将最小的那个分值设置为这个成员在输出有序集合的分值。
以下是一个 zset 取交集的实际例子
假设我们有两个有序集合,分别是用户A的粉丝列表和用户B的粉丝列表。我们想要找到同时关注用户A和用户B的共同粉丝,即取交集。
示例命令如下:
ZADD followers:A 1 user1
ZADD followers:A 1 user2
ZADD followers:A 1 user3
ZADD followers:B 1 user2
ZADD followers:B 1 user3
ZADD followers:B 1 user4
ZINTERSTORE common_followers 2 followers:A followers:B
ZRANGE common_followers 0 -1
以上命令执行了以下操作:
- 使用
ZADD命令向有序集合followers:A中添加用户A的粉丝。 - 使用
ZADD命令向有序集合followers:B中添加用户B的粉丝。 - 使用
ZINTERSTORE命令计算followers:A和followers:B两个有序集合的交集,并将结果存储到新的有序集合common_followers中。参数2表示参与计算的有序集合数量。 - 使用
ZRANGE命令获取有序集合common_followers中的所有成员,通过指定范围 0 -1 获取全部成员。
执行以上命令后,common_followers 中将包含用户A和用户B共同关注的粉丝列表。你可以通过查看 common_followers 的结果来获取共同粉丝的信息。
基数统计 HyperLogLog
HyperLogLog(HLL)是一种概率性数据结构,用于进行基数(cardinality)估算,即估计一个集合中不重复元素的数量。它的设计目标是在具有很大基数的集合上占用较小的内存,并且具有高效的插入和查询操作。
HyperLogLog通过使用固定的内存空间来估计集合的基数,而不会随着集合大小的增加而线性增加内存消耗。它基于哈希函数和位图技术,将元素映射到一个固定大小的位图中。通过统计位图中零位(leading zeros)的数量来估算集合的基数。
HyperLogLog的估算结果是概率性的,意味着估算值可能会有一定的误差。但是,在大多数实际应用中,HyperLogLog能够提供非常接近实际基数的估计结果,而且在空间效率和计算效率方面具有很大优势。
在Redis中,HyperLogLog是作为一种数据结构而被支持的,提供了PFADD、PFCOUNT和PFMERGE等命令用于插入元素、估算基数和合并多个HyperLogLog结构。它广泛应用于许多场景,例如统计网站的独立访客数量、统计广告点击次数、判断用户活跃度等。
使用实例
当使用 HyperLogLog 数据结构时,以下是一些具体的 Redis 命令和用法:
创建 HyperLogLog 结构:
PFADD hllset element1 element2 element3上述命令将元素 "element1"、"element2" 和 "element3" 添加到名为 "hllset" 的 HyperLogLog 结构中。
添加元素到 HyperLogLog 结构:
PFADD hllset element4 element5使用
PFADD命令将元素 "element4" 和 "element5" 添加到名为 "hllset" 的 HyperLogLog 结构中。估算 HyperLogLog 结构的基数:
PFCOUNT hllset使用
PFCOUNT命令获取名为 "hllset" 的 HyperLogLog 结构的基数估算值。合并多个 HyperLogLog 结构:
PFMERGE merged-hllset hllset1 hllset2 hllset3使用
PFMERGE命令将多个 HyperLogLog 结构("hllset1"、"hllset2"、"hllset3")合并为一个名为 "merged-hllset" 的 HyperLogLog 结构。
需要注意的是,以上命令仅是示例,你可以根据具体的需求和场景进行参数和结构的命名。此外,还可以使用其他一些相关命令来操作 HyperLogLog 数据结构,如 PFDEBUG、PFSELFTEST 等。
通过以上命令,你可以使用 HyperLogLog 数据结构进行基数估算,并根据需求进行元素的添加和合并操作。